※追記 こっちでやったほうが楽かもしれない.
koji-genba.hateblo.jp
ただAUTOMATIC1111版を使うやり方はすごくVRAM食うからこっちのやり方のほうがいい時もある.両方使うこともできるし好きに選べばいい.
==追記ここまで==
先駆者が無限にいるのにこれ書く必要ある?
novelAIではない
環境
windows11 22H2
Radeon RX6800XT
※wslではない
理屈上ではintel製GPUでもGPU無し環境でも動くとは思うけど未確認.
準備
python3.10.8
git
をインストール
適当な作業ディレクトリを用意して
github.com
をgit cloneする
Hugging Face – The AI community building the future.
にアカウント作成
OnnxDiffusersのセットアップ
適当に作業用のディレクトリを用意して
さっきcloneしたやつのsetup.batを実行.仮想環境作成とかパッケージのインストールとか走るからしばらく待つ.
終わったら
.\virtualenv\Scripts\activate
ターミナルの最初に(virtualenv)って出ればおk
ort-nightly-directmlインストール
ちょくちょくアプデされるからなるたけ新しいバージョンのやつ使ってください.
https://aiinfra.visualstudio.com/PublicPackages/_artifacts/feed/ORT-Nightly/PyPI/ort-nightly-directml/overview/1.15.0.dev20230126004
から
ort_nightly_directml-1.15.0.dev20230126004-cp310-cp310-win_amd64
をDLして
pip install ".\ort_nightly_directml-1.15.0.dev20230126004-cp310-cp310-win_amd64.whl" --force-reinstall
する.
huggingfaceログイン
https://huggingface.co/でSetting>Access TokensからToken作る.
そしたらターミナルで
huggingface-cli.exe login
してさっき作ったTokenを貼る.git credintialはnでいい.Login succesfulになればおk.
モデル用意
python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="Linaqruf/anything-v3.0" --output_path="model/anything-v3.0_onnx" python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="model/stable-diffusion-v1-4_onnx" python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="runwayml/stable-diffusion-v1-5" --output_path="model/stable_diffusion-v1-5_onnx"
全部やる必要はない.使いたいモデルだけでいい.ほかに使いたいモデルあるならそっちでいいし.
huggingfaceにあるモデルならおk.外の世界のモデルは知らん.
huggingface外のckptもonnxコンバートはできるはずだけど未確認.
モデルダウンロードしてckptからonnxコンバートするから非常に時間がかかる.昼飯でも食いながらゆっくり待つ.
テスト実行
txt2img_onnx.pyの29行目
"--model", dest="model_path", default="model/stable_diffusion_onnx", help="path to the model directory")
を
"--model", dest="model_path", default="model/anything-v3.0_onnx", help="path to the model directory")
みたいにさっき用意したモデルに合わせて書き換える.
そしたら
python txt2img_onnx.py --prompt="tire swing hanging from a tree" --height=512 --width=512
とかして適当に画像生成してみる.分かると思うけどpromptが生成内容指定プロンプト,heightとwidthが画像サイズ
初回はモデルデータの読み込みがあるため時間がかかる.outputフォルダにそれっぽい画像が出力されればおk.されなかったらどっかおかしいから頑張って何とかする.
GUI
python onnxUI.py
して表示されたURLをブラウザから開く.
あとは好きにやってください.
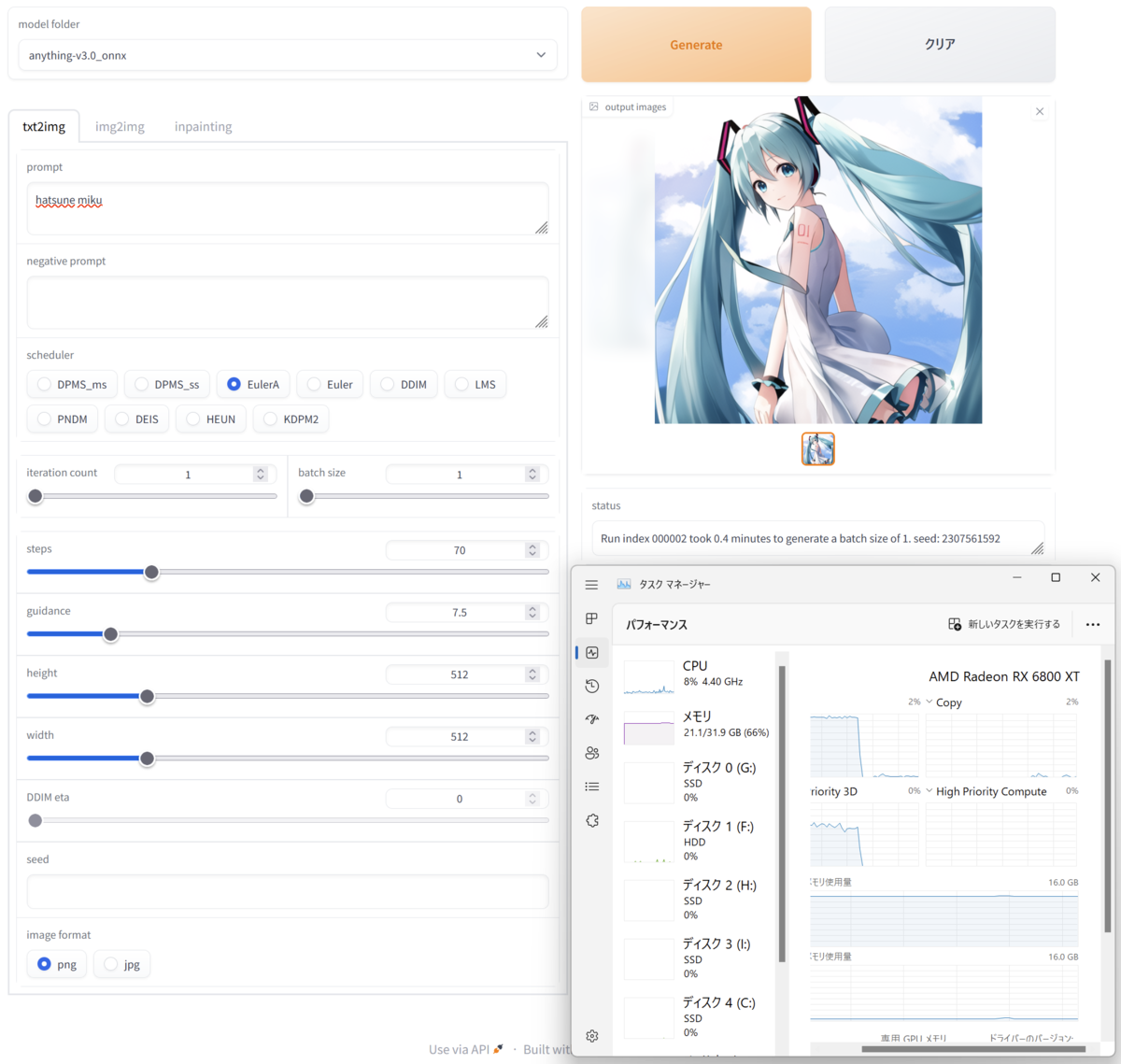
終わったらターミナルでCtrl+Cして終了.
2回目以降
#作業用フォルダの中でターミナル開いて# .\virtualenv\Scripts\activate python onnxUI.py
これだけ
その他
CPUonly
python txt2img_onnx.py --cpu-only --prompt="tire swing hanging from a tree" --height=512 --width=512
でCPUのみで実行.遅い.
アプデ
github.comからsetup.batだけDLして上書きして
.\setup.bat -update
でなんかアップデートできるらしいです.